

0 引言
近年来,随着人工智能技术的不断发展,基于视频识别的高速公路交通事件智能检测系统逐渐成为智慧交通领域的研究热点。这些系统通常需要设定道路检测区,以便对各种交通事件进行准确检测。对于应急车道停车、频繁变道等事件的检测尤为重要,因此需要进行车道级检测区设定。目前,大多数道路检测区的设定是通过人工在画面上标画完成的,这种方法不适合经常轮巡的云台摄像枪。因此,开发一种基于视频的高速公路车道级检测区自动设定方法,对于交通事件智能检测系统非常必要。为了实现车道级检测区的设定,首先必须对道路上的可行驶区域和车道线进行语义分割,然后通过标记算法对这些区域进行划分。尽管目前在自动驾驶领域已经有许多关于道路车道线和可行驶区域的语义分割算法研究,但在高速公路交通事件智能检测领域,这方面的研究相对较少。
早期的研究主要依赖人工设计的特征建立模型进行车道线检测。如Bertozzi等[1]提出的GOLD 系统是通过逆透视变换方法和模板匹配技术对车道线进行检测并确定车道线的具体位置;Betke等[2]提出了利用HSV(Hue, Saturation, Value)色彩空间特征对车道线进行识别;Lee[3]利用霍夫变换从图像中的边缘点提取直线实现对车道线的检测;刘富强等[4]通过自适应随机霍夫变换方法、Tabu serch算法和基于粒子滤波器的跟踪算法实现对车道线快速且稳定的检测,并同时解决了霍夫变换不能检测出弯道的问题。近年来,深度学习成为机器视觉领域最流行的技术,在图像分类、目标检测和语义分割等方面都有广泛的应用。Wang等[5]受到语义分割技术的启发,提出了LaneNet网络,可以检测到可变车道的数量。为了提高对被遮挡的车道线的检测准确度,Pan等[6]提出了空间卷积神经网络(Spatial Convolutional Neural Network, SCNN)。SCNN将传统的深层逐层卷积推广到特征映射中的逐片卷积,实现了层中行与列之间的像素间消息传递,从而推理出被遮挡的车道线位置。Wu等[7]为了提高对车辆、车道线和可行驶区域的识别效率并减少计算资源占用,提出了一种多任务学习网络(YOLOP),它可以基于同一条主干网络同时检测出车辆、车道线和可行驶区域。与传统方法相比,基于深度学习的车道线和可行驶区域的检测方法的鲁棒性更好、泛化性能更强,但由于其参数量大、计算复杂度高和占用的计算资源多,限制了其在实际工程中的应用。U-Net[8]是一种专为图像分割任务设计的神经网络结构,于2015年被首次提出。该模型以其对称的编码器-解码器结构和跳跃连接闻名,这些特点使其能够在保留空间信息的同时有效地进行特征提取和重建。U-Net在医学图像分析中尤其受到青睐,因为它能够处理小样本数据集并生成精确的分割结果。MobileNet[9⇓-11]是由谷歌公司开发的一种轻量级深度神经网络,旨在为移动和嵌入式视觉应用提供高效的计算解决方案。其核心是深度可分离卷积,这种卷积操作将标准的卷积分解为一个深度卷积和一个1×1卷积,显著减少了参数量和计算成本,同时保持了网络的性能。
在既有研究中,经典的语义分割网络(如U-Net)和主流的轻量化网络(如MobileNet)已经在多个领域展示了其强大的性能。然而,这些模型在公路监控场景下的车道线和可行驶区域检测方面仍存在一些不足。特别是当其布署在老旧设备上时,模型的参数量和内积运算量较大,导致计算资源消耗高,难以满足实时性要求。此外,目前缺乏专门针对公路监控场景的车道线和可行驶区域检测数据集,这限制了模型在该领域的应用。本文的研究旨在解决上述问题,通过改造U-Net语义分割网络,利用MobileNet系列模型的轻量化特性,实现在保持工程应用精准度的基础上尽量轻量化网络。具体而言,首先收集并标注一个基于公路监控图像的车道线和可行驶区域的数据集,以填补现有数据集的空白。然后,从模型参数量、内积运算量和分割性能指标等3个方面与SegNet和U-Net进行比较,验证所建语义分割模型的优势。接下来,基于连通域分析的标记算法对车道线和可行驶区域进行标记,划分出上下行区域和不同位置的车道,以期最终实现车道线检测区的自动设定,从而提高交通事件识别的准确率,为高速公路交通事件智能检测提供一种高效且轻量化的解决方案。
1 车道线和检测区的语义分割算法
1.1 U-Net网络结构的特点
U-Net图像分割算法最早是用于医疗行业的病理图像分割,由于其出色的图像分割性能,该算法结构逐渐被应用到其他行业,例如路面裂缝图像的分割等。U-Net使用了编码器-解码器结构,如图1所示。该网络结构最主要的一个特点是使用了跳层连接,通过跳层连接将浅层的特征信息与深层的语义信息相结合,从而提高图像分割的性能。U-Net是一个十分经典的网络,后续很多的语义分割网络都受到其启发或者在其基础上进行改进。因此,本文将U-Net的基本结构作为语义分割模型的骨架。
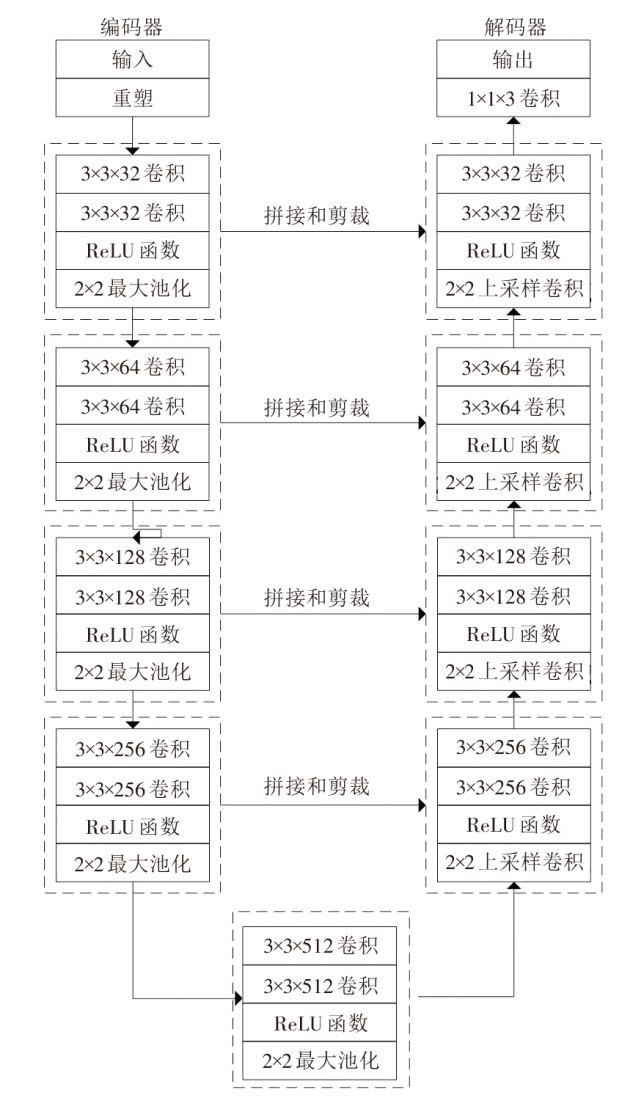
1.2 深度可分离卷积结构
标准卷积的过程如图2所示。例如,输入一个64×64×3的特征图,经过5×5×3的卷积核卷积后得到60×60×1的特征图,若一共有512组上述卷积核,则会得到60×60×512的特征图。其参数量为5×5×3×512,内积运算量为5×5×3×512×60×60。
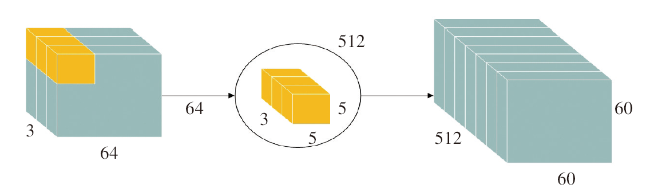
而深度可分离卷积的过程分以下两步。
第一步为逐通道卷积,其过程如图3(a)所示。与标准卷积不同,逐通道卷积先将与输入特征图通道数相同的卷积核拆分成单通道的形式,然后对输入特征图的每一个通道进行卷积操作,从而得到与输入特征图通道数一致的输出特征图。例如,输入一个64×64×3的特征图,经过5×5×1×3的卷积核卷积后得到60×60×3的特征图,输入和输出的深度都为3。其参数量为5×5×3,内积运算量为5×5×3×60×60。
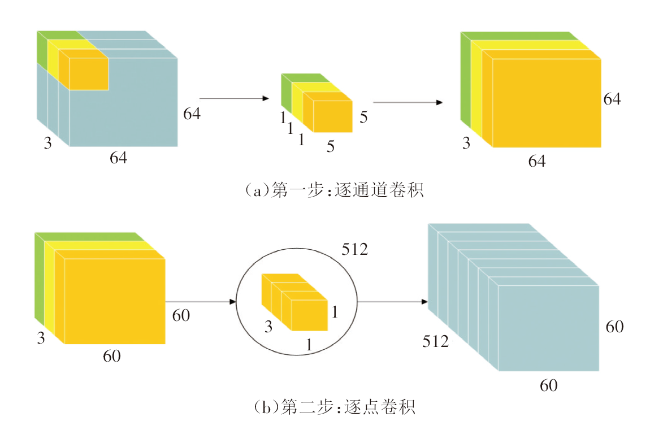
第二步为逐点卷积,其过程如图3(b)所示。其输入为上一步逐通道卷积的输入,即60×60×3的特征图,在逐点卷积中采用512个1×1×3的卷积核对上一步输出的特征图进行卷积操作,从而使输出的特征图和标准卷积的维度一致,均为60×60×512。其参数量为3×512,内积运算量为3×512×60×60。
为了探究深度可分离卷积的轻量化性能,将标准卷积与深度可分离卷积的参数量和内积运算量的计算过程用字母表示并制作成表,如表1所示。假设输出特征图的维度为 ,有N组尺寸为 的卷积核,每组进行 次内积计算,则标准卷积的参数量为 ,运算量为 。而深度可分离卷积中的逐通道卷积部分参数量为 ,运算量为 ;逐点卷积部分的参数量为 ,运算量为 。
表1 标准卷积与深度可分离卷积的对比 |
| 卷积类型 | 参数量 | 运算量 | 比例 |
|---|---|---|---|
| 标准卷积 | Dk×Dk×M×N | Dk×Dk×M×N×Dw×Dh | 1 |
| 深度可 分离卷积 | Dk×Dk×M+ M×N | Dk×Dk×M×N×Dw×Dh+ M×N×Dw×Dh | 1/N+ 1/Dk2 |
由表1可知,深度可分离卷积的参数量和内积运算量均只有标准卷积的1/N+1/Dk2。在卷积操作中,N的值一般较大,例如32, 64, 256等,而Dk的值一般较小,例如3, 5, 7等。因此,深度可分离卷积的参数量和内积运算量至少能减少数倍,这也是 MobileNetV1实现轻量化的关键。
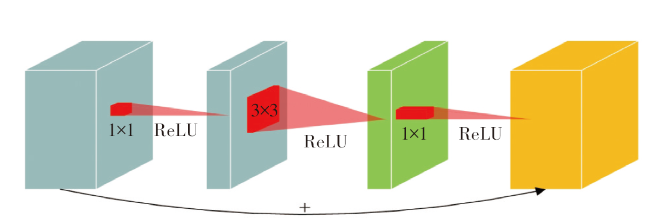
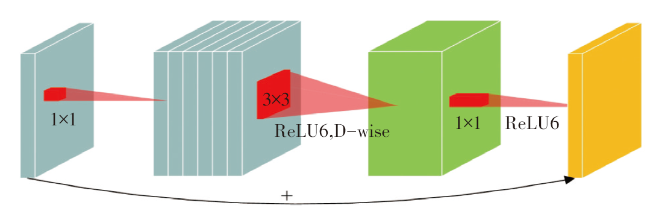
1.3 倒置残差结构
1.4 轻量化网络模型设计
基于上述分析,本文在U-Net网络架构的基础上,采用深度可分离卷积和倒置残差等结构进行轻量化设计以满足硬件资源和算力资源有限的条件下车道线和检测区的语义分割需求。本文基于U-Net网络架构设计了3个网络模型。第1个网络模型只对U-Net网络架构的编码器进行轻量化改造,如图6(a)所示,本文将其命名为Road-NetV1,简称R-NetV1。R-NetV1将U-Net网络架构中编码器的标准卷积结构替换成了倒置残差结构。第2个网络模型只对U-Net网络架构的解码器进行轻量化改造,如图6(b)所示,本文将其命名为Road-NetV2,简称R-NetV2。R-NetV2将U-Net网络架构中解码器的标准卷积结构替换成了倒置残差结构。第3个网络模型对U形网络架构的解码器和编码器都进行了轻量化改造,如图6(c)所示,本文将其命名为Road-NetV3,简称R-NetV3。R-NetV3将U-Net网络架构中编码器和解码器的标准卷积均替换成了倒置残差结构。

相较于U-Net网络结构,R-Net系列网络将U-Net中连续两个标准卷积替换成一个倒置残差模块,即倒置残差模块仅重复堆叠1次,从而减少模型的参数量和内积运算量。在图7所示的倒置残差模块中,首先对输入的特征图进行1×1卷积并可以通过预设的扩张倍数增加通道数,接着进行3×3的逐通道卷积(Depth-Wise Convolution, DW-Conv),最后通过1×1的逐点卷积降低通道数并与输入的特征图信息直接相加得到输出特征图。本文将倒置残差模块1~5的扩张倍数均设为3,将倒置残差模块6~9的扩张倍数均设为1,即将编码器中的倒置残差模块的扩张倍数均设为3,将解码器中的倒置残差模块的扩张倍数均设为1。这样设置是因为编码器是用于提取输入特征图的特征,为了使网络模型能在高维空间提取特征,所以编码器中的倒置残差模块的扩张倍数均设置为3,以增加特征图的通道数。而解码器只是将编码器提取到的特征解释出来,因而为了使网络模型更加轻量化,将倒置残差模块的扩张倍数均设置为1。
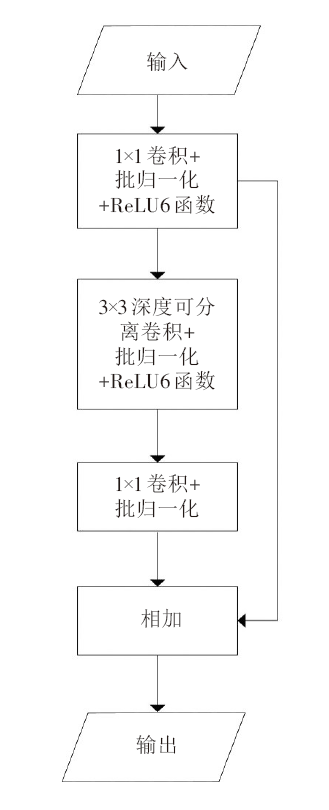
2 基于连通域分析的车道线和检测区标记算法
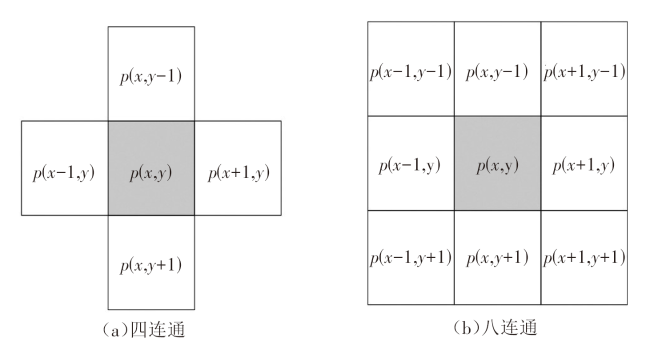
图像的连通域是指图像中具有相同像素值并且位置相邻的像素组成的区域。假设在像素为W×h的二值图像中,记 为坐标 的像素,其中 。图像内的像素值只有0和1,假设0代表背景像素,1代表对象像素。在连通域分析算法中,连通关系有两种:四连通和八连通,如图8所示。任意像素 的上下左右4个像素,即 和 为其四连通像素。而八连通像素则是在四连通像素的基础上加上4个对角相邻像素,即 和 。
步骤1:第一次遍历图像时会给每一个非0像素赋予一个数字标签。
步骤2:当某个像素的上方和左侧邻域内的像素已经有数字标签时,取二者中的最小值作为当前像素的标签,否则赋予当前像素一个新的数字标签。
步骤3:第一次遍历图像时,同一个连通域可能会被赋予一个或者多个不同的标签,因此第二次遍历时需要将这些属于同一个连通域的不同标签合并。
步骤4:取连通域中标签的最小值作为数字标签,从而实现同一个连通域内的所有像素具有相同的数字标签。
3 车道线和检测区的语义分割实验
3.1 实验数据集

3.2 实验设置
实验设备的 GPU 型号为 NVIDIA GeForce RTX 3060,基于深度学习框架为Pytorch搭建多个算法模型。训练时,采用随机梯度下降的方式,每批次数量设为 2,初始学习率设为 0.001,动量为0.9,用测试集去评价训练完成的模型。
3.3 实验结果分析
将本文设计的R-Net系列3个版本模型R-NetV1, R-NetV2, R-NetV3与SegNet及U-Net模型进行对比,结果如表3所示。
表3 各模型的实验结果对比 |
| 模型 | IoU(%) | MIoU (%) | 模型参数量/MB | 内积运算 量/GB | ||
|---|---|---|---|---|---|---|
| 车道线 | 检测区 | 背景 | ||||
| SegNet | 68.3 | 95.4 | 94.9 | 94.1 | 28.08 | 502.03 |
| U-Net | 58.3 | 91.8 | 92.7 | 91.0 | 7.76 | 174.88 |
| R-NetV1 | 54.7 | 89.8 | 91.5 | 89.3 | 3.76 | 129.56 |
| R-NetV2 | 52.5 | 91.5 | 92.5 | 90.6 | 4.76 | 65.63 |
| R-NetV3 | 39.7 | 88.0 | 90.5 | 87.6 | 1.03 | 20.30 |
从模型的参数量来看,本文设计的R-Net系列的3个模型的参数量均小于5 MB,其中R-NetV3的参数量仅为1.03 MB。相比之下,U-Net的参数量为7.76 MB,SegNet的模型参数量更是高达28.08 MB。这也证明了可以利用倒置残差模块去改造传统的卷积神经网络,从而实现网络模型的轻量化。另外,从R-Net系列3个模型的参数量来看,用倒置残差模块替换标准卷积模块的数量越多,其模型参数量越少,即网络模型的轻量化效果越好,这也充分证明倒置残差模块的轻量化性能很好。
从模型的内积运算量来看,U-Net的内积运算量为174.88 GB,而SegNet的内积运算量高达502.03 GB。相比而言,R-Net系列3个模型的内积运算量都有不同程度的减少,其中R-NetV3的内积运算量仅为20.3 GB。在同样的软件环境和硬件资源条件下,内积运算量越小,则模型的推理速度越快,即模型的实时性越好。
从语义分割的准确度来看,由于模型需要将图片分割成车道线、可行驶区域和背景,因而本文分别以IoU和MIoU作为准确度的评价指标。交并比(Intersection over Union, IoU)是语义分割的标准度量,即真实值和预测值的交集与并集之比。均交并比(Mean Intersection over Union, MIoU)是指测试数据集中每一类交并比的平均值。由表3可知,从车道线的分割效果来看,SegNet模型的分割效果最好,其IoU值达到68.3%,而R-NetV3模型的分割效果最差,其IoU值只有39.7%。从检测区的分割效果来看,SegNet模型的分割效果也是最好的,其IoU值达到95.4%,而R-NetV3模型的分割效果也是最差,其IoU值为88.0%。从模型的总体分割效果来看,分割效果最好的SegNet模型的MIoU值达到94.1%,而分割效果最差的R-NetV3模型的MIoU值只有87.6%。通过以上分析可知,参数量越大的模型,其语义分割准确度一般也越高。本文所提的R-NetV2网络的分割性能指标MIoU与U-Net网络几乎相同,但其模型参数量减少了38.7%,内积运算量减少了62.5%。
部分分割结果可视化图对比如图10所示。从测试结果可视化的角度看,SegNet的分割效果最好,如图10中c组图像所示,车道线即便被车辆遮挡,SegNet也能够推理出来,而无论是U-Net还是R-Net系列模型都不能推理出被车辆遮挡后的车道线。另外,对于车道线中的虚线,SegNet根据虚线推理出车道分割线的性能很好,而其他模型或多或少都有断点,其中R-NetV3的断点最多,间隔也最大。虽然SegNet的图像分割效果很好,但由于其模型参数量和内积运算量均很大,并不适合在硬件资源和算力资源有限的场景中使用。而U-Net, R-NetV1和R-NetV2无论在车道线还是检测区分割上,其效果差别都不大,但R-NetV1和R-NetV2的模型参数量和内积运算量均比U-Net模型小。与U-Net相比,R-NetV1的模型参数量减少了51.5%、内积运算量减少了25.9%,R-NetV2的模型参数量减少了38.7%、内积运算量减少了62.5%。因而,在需要保证较好的语义分割效果时,硬件资源和算力资源有限的场景下可以选择R-NetV1或R-NetV2模型,其中R-NetV1模型更适合存储等硬件资源不足的场景,而R-NetV2模型则更适合算力资源有限的场景。虽然R-NetV3的分割效果一般,但相比U-Net,其模型参数量只有1.03 MB、内积运算量只有20.3 GB,分别减少了86.7%和88.4%,因而在分割性能要求不高、硬件资源和算力资源极度有限的场景下,可以选择R-NetV3。

本文所提的方法针对的是高速公路上的云台摄像枪,在云台摄像枪转动时虽然也需要及时更新车道线和检测区的识别结果,但不像自动驾驶汽车那样需要低时延和持续地感知车道线和检测区。另外,大部分时间云台摄像枪都是固定不动的。通过以上分析可以得出,要在保证一定分割性能的同时尽可能减少对算力资源的占用,适合选择模型参数量和内积运算量都较少的R-NetV2作为语义分割模型。
4 车道线和检测区的标记实验
4.1 实验模型和数据集
车道线和检测区的标记是基于车道线和检测区的语义分割结果进行的。由前文可知,根据实际的应用场景和需求,选用R-Netv2作为语义分割模型。同时考虑到车道线的分割结果可能不连续,比如车辆的遮挡或者虚线等原因,本文将连续多帧图像的分割结果叠加作为基于连通域分析的车道线和检测区标记算法的输入。因而,本文选择100个短视频作为标记算法的测试集,每个短视频包含20帧图像。另外,本文将正确标记定义为同一对象有同样的标记像素值、不同对象有不同的标记像素值,不符合正确标记定义的均判断为错误标记。
4.2 标记前的预处理方法
基于连通域分析的标记算法是根据像素点间的连通关系来标记不同对象区域,因而分割结果需要保证不同对象的像素不连通、同一对象的像素完全连通。图11为预处理前后的对比图。

然而,即便当前精确度最高的语义分割模型输出的车道线分割结果也存在离散的分割区域,如图11(a)中的黑色圆圈所示。为了提高分割区域的精确度和完整性,选择性能更好的语义分割模型也是不经济的,因为其模型参数量和内积运算量会增加很多,不适宜工程应用。为了减少离散分割区域的影响,本文提出两种预处理方法。第一种方法是通过阈值剔除离散区域。根据实践经验和工程需求,无论车道线还是检测区,小于最大分割区域的1/10均会被剔除。第二种方法是通过叠加多帧分割结果使其融合连通。车道线先利用第一种方法进行处理,再利用第二种方法进行处理,而检测区只利用第一种方法进行处理。经过上述处理,从图11可以看出,面积较小的离散分割区域被剔除,对于车道线区域,通过叠加多帧分割结果,车道线分割区域逐渐变大并连通。然而,由于只叠加了1帧分割结果,一些车道线区域未能完全连通。
4.3 实验结果分析
表4 第1帧~第10帧的平均准确率 |
| 帧序号 | 平均准确率(%) | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||||||||||||
| 检测区 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | ||||||||||||
| 车道线 | 80.47 | 87.91 | 91.31 | 91.46 | 92.05 | 93.44 | 94.04 | 94.57 | 94.57 | 95.10 | ||||||||||||
| 帧序号 | 平均准确率(%) | |||||||||||||||||||||
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||||||||||||
| 检测区 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | ||||||||||||
| 车道线 | 95.58 | 95.58 | 95.58 | 95.58 | 94.39 | 94.39 | 94.39 | 93.79 | 93.79 | 93.32 | ||||||||||||
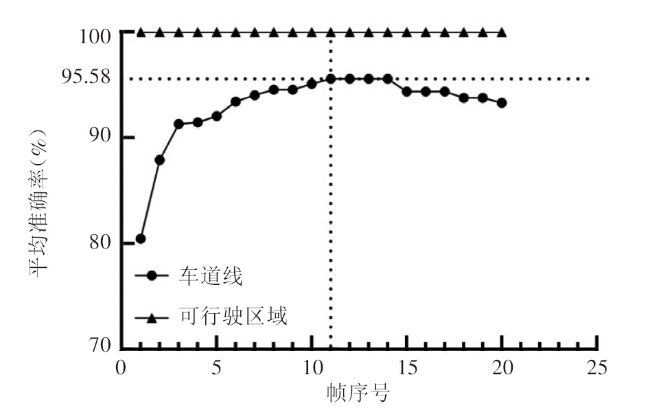
从车道线标记的平均准确率变化趋势可以看出,叠加分割结果有助于提高车道线标记的准确率,但平均准确率并不随着叠加帧数的增加而不断增加,而是先上升,再保持稳定,最后略微下降。最后阶段平均准确率出现下降的原因是:在实验过程中,随着叠加帧数的增加,车道线识别区域逐渐超出其真实区域,这可能导致相邻的车道线区域连通,使得连通域标记算法将两条车道线误标记为一条。如图13中的局部图所示,第18帧图像中黑色图圈内的车道线1和车道线2的分割结果已连通,因而被标记算法标记为同一条车道线。

4.4 标记后的拟合方法


从图15可以看出,无论公路、桥梁还是隧道场景,无论白天还是夜晚,车道线都能被准确检测且完整地分割。
5 结束语
本文提出了一种基于视频的高速公路车道级检测区自动设定方法。实验结果表明,该方法实现了精准设定和快速复位,对确保监控系统的连续高精度监测具有重要作用。主要成果包括:
1)提出了R-Net系列轻量化模型,实现了高速公路检测区和车道线的语义分割。在所构建的数据集上,R-NetV2模型的MIoU达到90.6%,参数量减少了38.7%,内积运算量减少了62.5%。
2)提出了基于连通域分析的车道线和检测区标记算法,车道线标记准确率最高可达95.58%,检测区标记准确率可达100%。
3)提出了阈值处理和叠加多帧分割结果的预处理方法,显著提高了标记准确率。同时指出了叠加帧数过多可能导致标记错误,相邻车道线融合连通被误标记为同一条车道。
4)提出了利用二次方程拟合车道线标记结果的方法,实现了完整且平滑地分割车道。
通过以上研究,本文有效解决了高速公路智能监控系统中车道级检测区的自动设定问题,提高了交通事件识别的准确性和效率。创新性地提出了轻量化模型R-Net系列、基于连通域分析的标记算法以及阈值处理和叠加多帧分割结果的预处理方法。然而,本研究仍存在一些局限,如在复杂场景下的鲁棒性有待进一步验证。未来研究方向包括优化算法以提高其在复杂场景下的性能,并探索更多应用场景以扩展其应用范围。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}